Research
Artificial Intelligence
Hardware Research
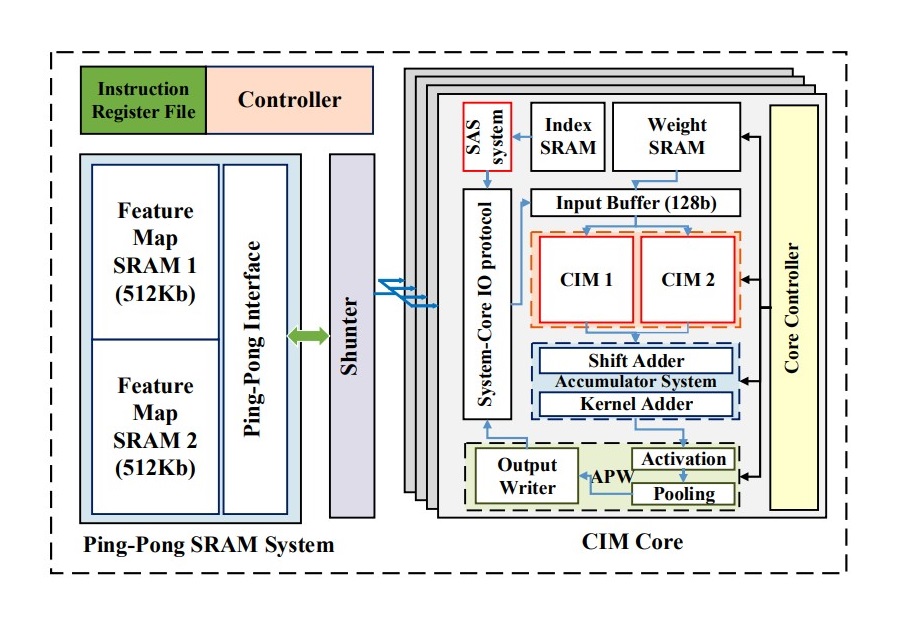
MARS: Multi-macro Architecture SRAM CIMBased Accelerator with Co-designed Compressed Neural Networks
Convolutional neural networks (CNNs) play a key role in deep learning applications. However, the large storage overheads and the substantial computational cost of CNNs are problematic in hardware accelerators. Computing-inmemory (CIM) architecture has demonstrated great potential to effectively compute large-scale matrix–vector multiplication. However, the intensive multiply and accumulation (MAC) operations executed on CIM macros remain bottlenecks for further improvement of energy efficiency and throughput. To reduce computational costs, ......
Algorithm Research
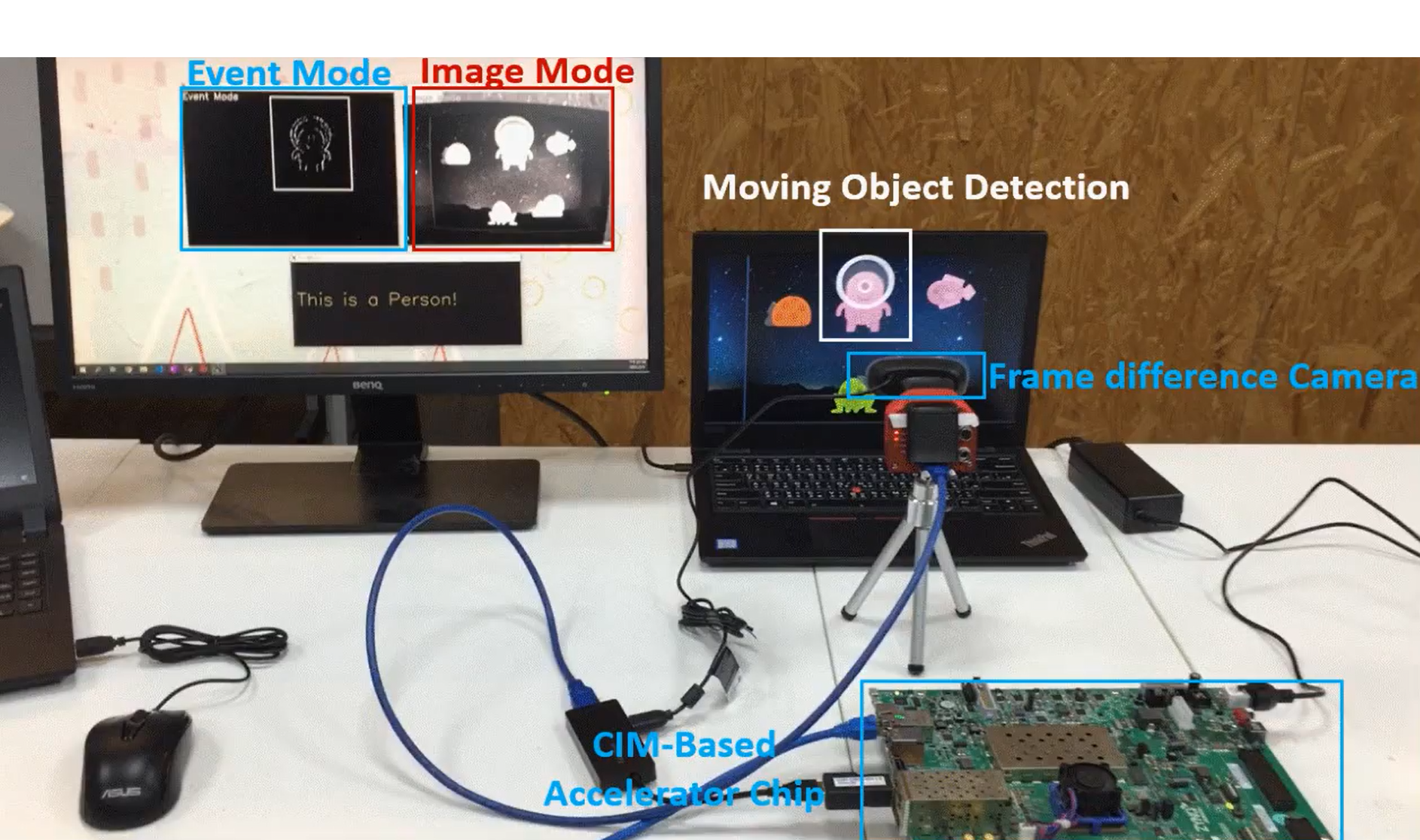
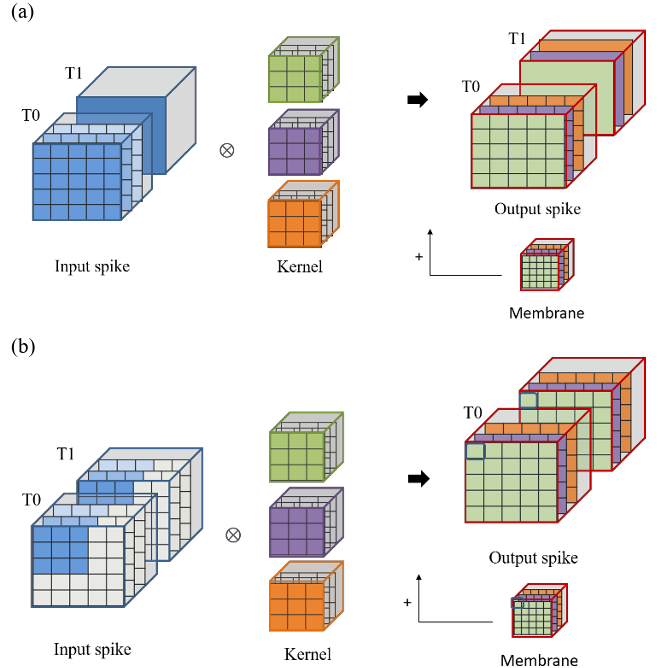
A 104.76-TOPS/W, Spike-Based Convolutional Neural Network Accelerator with Reduced On-Chip Memory Data Flow and Operation Unit Skipping
The energy efficiency of artificial intelligence networks must be increased if they are to be implemented on edge devices. Brain-inspired spiking neural networks (SNNs) are considered potential candidates for this purpose because they do not involve multiplication operations. SNNs only perform addition and shifting operations. SNNs can be used with a convolutional neural network (CNN) to reduce the required computational power. The combination of an SNN and a CNN is called a spiking CNN (SCNN). To achieve a high operation speed with an SCNN, a large memory, which occupies a relatively large area and consumes a relatively large amount of power, is often required. In this paper, a data flow method is proposed to reduce the required on-chip memory and power consumption and to eliminate the operation unit skipping of a high-sparsity SCNN ......
System Research
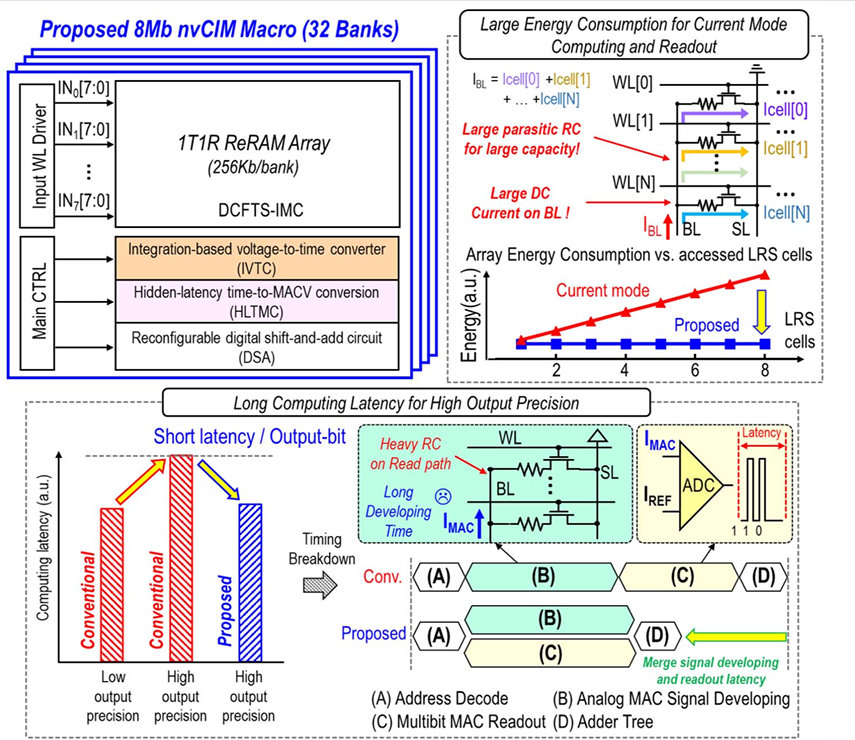
An 8-Mb DC-Current-Free Binary-to-8b Precision ReRAM Nonvolatile Computing-in-Memory Macro using Time-Space-Readout with 1286.4 - 21.6TOPS/W for Edge-AI Devices
Edge-AI devices are increasingly reliant on nonvolatile computing-in-memory (nvCIM) macros to perform multiply-and-accumulate (MAC) operations with high efficiency and low power consumption. This paper presents an innovative 8-Mb DC-current-free binary-to-8b precision ReRAM nvCIM macro that leverages a novel Time-Space Readout mechanism. The proposed macro, designed using a 22nm process, addresses the primary challenges faced by current-mode nvCIMs, including limited energy efficiency,output precision,and high computing latency. By introducing a DC-current-free time-space based in-memory computing (DCFTS-IMC) scheme, an integration-based voltage-to-time converter (IVTC), and a hidden-latency time-to-MACV conversion (HLTMC) scheme, we achieve significant improvements in power consumption and latency without sacrificing precision......